Shortcut to seniority
Home
Go to main page
Section level: Junior
A journey into the programming realm
Section level: Intermediate
The point of no return
Section level: Senior
Leaping into the unknown
Go to main page
A journey into the programming realm
The point of no return
Leaping into the unknown
A critical section (or critical region) refers to a piece of code that accesses a shared resource that should not be simultaneously accessed by more than one thread. Therefore, we need to implement a synchronization mechanism when entering and leaving the critical section.
We can think of it like this: We have two or more processes that want to access the same resource, at the same time.
In a multi-threaded environment, we cannot make any assumptions on when the code will be executed by the CPU.
An example would be when multiple threads want to allocate some memory from the heap. If the access to the heap is not synchronized, the OS will find the first chunk of memory that is not used and provide it to all threads – Each further writes on that memory address will cause problems to the other threads, because all of them believe to have full control over that memory buffer.
Critical sections (Areas of code that should be limited to only one thread at a time) should be protected by synchronization mechanisms, but only in the following scenario:
Otherwise, each consecutive call to a read-only function should provide the same result each time, if the state is not being modified (The sum of two variables will always be the same, for example).
A race condition is a behavior where the outcome of the situation depends on the relative ordering of the execution of operations on two or more threads.
Race condition will lead to bugs, crashes, error notification, or the shutdown of the application, and they are hard to find, debug, or reproduce. Race conditions can be avoided by using synchronization mechanisms.
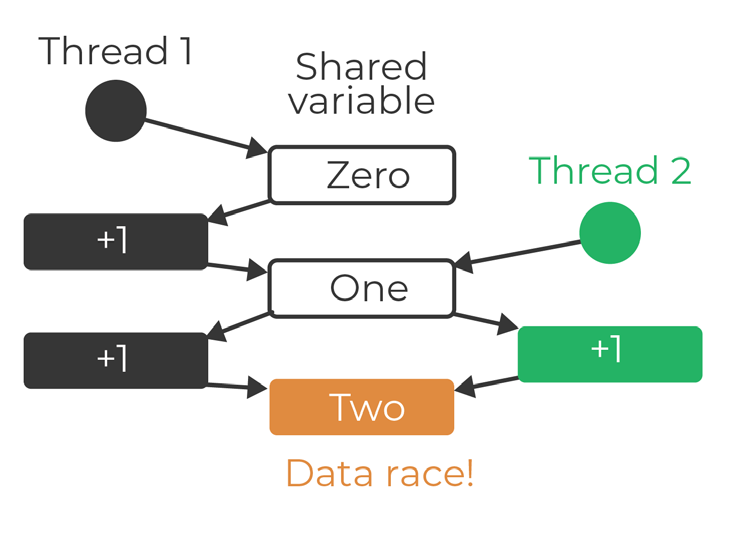
A data race is a specific type of race condition, which happens when there are two conflicting memory operations that access the same memory location, and one of them is a write. A program with data races usually has unpredictable behavior.
A mutex is a synchronization / locking mechanism that is used to protect critical sections, by limiting the access to a shared resource. Mutually exclusive access is guaranteed by the fact that only one thread can hold a mutex at any given time, and that the shared resource is only accessed by the thread holding the mutex.

Only one thread can acquire the mutex, and the ownership is granted to that thread. This means that only the owner of the mutex can release it.
Because the mutex knows its current owner, the Operating System can provide priority inversion safety. This means that it can temporarily increase the priority of the owner thread in order to have the highest priority among all other threads waiting to get the mutex.
They also provide deletion safety, where the task holding the mutex cannot be deleted by mistake.
The Operating System will also normally release all the mutexes that a thread holds when it terminates.
A semaphore is a synchronization/signalling mechanism. Internally, it’s an object that contains a private counter, a waiting list of processes, and two public methods (signal, and wait).
The counter refers to the number of threads that can receive access to the semaphore.
The wait function decreases the count and adds the caller to the waiting list if it cannot provide access.
The signal function increases the count and removes the caller from the waiting list, providing it access to the section.
Similar to mutex, a semaphore is used to protect critical sections, but it allows access to more than one thread at the same time. Semaphores contain a count which refers to the number of threads that can enter a critical section. If a semaphore has a count of 3, it means 3 different threads can enter the critical section. A 4th one will have to wait until one of the other 3 threads are leaving an empty seat at the table.

A binary semaphore is a semaphore with a count of 1 (which allows access to only one thread).
Although it seems similar to a mutex, they should be treated separately.
Unlike mutexes, threads do not have ownership over semaphores, and the Operating System cannot release (increment) the counter if the thread that uses it terminates, as it doesn’t know who’s supposed to increase its counter.
As mentioned before, mutexes are a locking mechanism, while the semaphores are a signalling mechanism.
With semaphores, a thread that is waiting on a semaphore can be signaled by another thread, while with the mutex, the mutex can only be signaled by the thread that locked it.
While a mutex is used for mutual exclusion, a semaphore is used for flow control, restricting the number of threads that execute a block of code.
Atomics types are a mechanism of synchronizing data access. Operations that are done on these types are atomic / indivisible (no other operations can interleave with any part of an atomic operation), but they require synchronization between processor cores, synchronization which increases the time required to access it, due to the fact that the cores need to communicate and coordinate the memory access.

Atomic types provide guarantess regarding the atomicity and ordering of operations.
Without atomics, if multiple threads increment a value, we will have a data race.
That is because incrementing a value is a read-modify-write operation (Read value from memory, modify it, write it back into memory).
Therefore, if two or more threads work on the same variable, they can both read the value from memory (let’s say an integer with value 1), increment it (both of them increment it to 2) and then write it in memory (both of them write the value 2 back to memory).
Since we have no synchronization between threads, each CPU reads the value from its cache, increment it, and write it back into cache, and eventually the value will propagate back into memory. The threads don’t know anything about the others threads.
Atomic objects are free from data races – if one thread writes to an atomic object while another thread reads from it, the behavior is well-defined. Since atomics are guaranteed to execute as a single transaction, other threads will see the state before the operation started, or after it finished.
Atomic operations are special hardware instructions (the atomicity is guaranteed at hardware level).
When you attempt to enter a critical section, you’ll most likely be using a sync mechanism to ensure you will most likely be using a sync mechanism to ensure that only one thread will use that resource at any given time.
If a thread makes a request to use a resource, and the system cannot grant it (because there’s already another thread working with the resource) the thread that requested the resource is put on hold until it can acquire the resource.
A deadlock is a situation in which two threads are blocking each other simultaneously. This situation occurs when there are two resources involved, each of them being held by one thread, and both threads require the resource which is held by the other thread in order to continue.
A deadlock occurs if all of the following conditions are true:
We need to find a solution so that at least 1 condition is false, in order to avoid deadlocks.
Removing the mutual exclusion of a resource is most likely not possible, because the resource must be accessed exclusively.
Hold and wait: A solution would be to not allow a process to hold a resource and ask for another one.
No preemption: A solution would be to yield any held resources if a thread is unable to acquire all of the required ones.
Circular waiting: A solution would be to have the resources acquired in a particular order. This way, if one thread already acquired the first one, all the other threads will be waiting for that resource instead of trying to acquire another one instead.
mutex _mx1;
mutex _mx2;
void first_function() {
_mx1.lock();
this_thread::yield();
this_thread::sleep_for(3s);
_mx2.lock();
cout << "I have acquired both mutexes";
}
void second_function() {
_mx2.lock();
this_thread::yield();
this_thread::sleep_for(3s);
_mx1.lock();
cout << "I have acquired both mutexes";
}
int main() {
thread thread1(first_function);
thread thread2(second_function);
thread1.join();
thread2.join();
return 0;
}
So what happens is that we have two global mutexes (Lines 1-2) which are locked from two functions (Lines 5 / 8 / 13 / 16), functions that are executed on two separate threads (Lines 21-22).
Thread1 (Line 21) will execute func12, which will lock mutex _mx1, and then hint the CPU (yield from line 6) that his work is done and can be removed from the CPU. Afterwards, it sleeps for 3 seconds so the other thread can catch up and lock the second mutex.
What happens is that thread1 will get mutex _mx1 and sleep.
While it sleeps, thread2 will get mutex _mx2 and sleep.
When both of them wake up:
Therefore, none of them will be awaken until the mutex they hold is released, and they can’t continue work because the second mutex that they want to acquire is already owned by the other one.
A solution would be to use non-blocking functions that return false if they are unable to lock the mutex, instead of blocking until it’s available.
Another solution would be to attempt to lock all mutexes in the same order. The problem with this case is that we have two mutexes and they are requested in a different order.
Assuming that both of them would be in the same order (_mx1, _mx2), the second thread will wait on line 13, for the first mutex, which is already owned by the thread executing line 5.
Therefore, the first thread will lock both mutexes, finish its work, and then release them for the second thread to continue its work as well.
A livelock is similar to deadlock, but the threads are not in the waiting state (like in the deadlock case). The threads try to make progress, but they repeat the same interaction, in response to any change that occurs in the other thread, so no work gets done.
To avoid this, the locking sequence should be ordered in a hierarchical way. Let's look at code snippet - like in the previous example, we have two threads that run two different functions.
Each of them lock the other mutex (Lines 5 and 14), and then yield and sleep for 3 seconds.
mutex _mx1;
mutex _mx2;
void first_function() {
_mx1.lock();
while (true) {
this_thread::yield();
this_thread::sleep_for(3s);
if (false == _mx2.try_lock()) continue;
cout << "I have acquired both mutexes";
}
}
void second_function() {
_mx2.lock();
while (true) {
this_thread::yield();
this_thread::sleep_for(3s);
if (false == _mx1.try_lock()) continue;
cout << "I have acquired both mutexes";
}
}
int main() {
std::thread thread1(first_function);
std::thread thread2(second_function);
thread1.join();
thread2.join();
return 0;
}
After three seconds, they attempt to lock the second mutex, and because they fail (Lines 9 and 18) they yield and sleep again for another three seconds.
In contrast with the deadlock example, the threads are active every three seconds, but they don’t make any progress whatsoever.
Process communication is the mechanism that allows the processes to communicate with each other. There are multiple techniques that allow such communication, and among them are the following:
Pipes are used to communicate between two or more related or interrelated processes.
Unnamed pipes are a unidirectional communication channel that can be accessed only by the processes that share the same ancestors (child/parent processes).
The communication is achieved by one process writing into the pipe, and another one reading from it.
For a two–way communication channel, you’ll need to use two pipes – one for reading from, and another one for writing into.
Named pipes can be accessed by two or more un-related processes, but all processes must know the name of the pipe they connect to. Unlike unnamed pipes, the named pipes are bidirectional channels – all connected processes can read and write to the same channel.
Shared memory refers to memory that is shared between two or more processes.
The operating system allocates a block of memory and shares it to multiple processes, and they can further read and write upon. This method can also be used to conserve memory space by having only a single piece of data instead of multiple copies of it.
A socket is a way of connecting two nodes on a network, so they can communicate with each other. The socket can also be used for processes on the same computer, but they are mainly used for connecting two separate computers.
A message queue is an asynchronous service to service communication. Messages are stored on the queue until they are processed by a consumer. Each message can be processed only once.
Signals are asynchronous notifications that are sent to a process or to a thread within the same process to notify it about an event. The signals (events) are pre-defined constants.
A memory-mapped file is a file that is mapped to RAM, which can be modified by changing memory addresses directly instead of writing to the file stream.
The dining philosophers problem is an example problem often used in concurrent algorithm design, to show synchronization issues and techniques for resolving them. This problem was originally formulated by Dijkstra when he was a student.
Five philosophers sit at a round table with bowls of spaghetti. Forks are placed between each pair of adjacent philosophers.
Each philosopher can do two actions: think, and eat.
A philosopher can eat only when they have both left and right forks.
Each fork can be held by only one philosopher -> a philosopher can use the fork only if it’s not being used by another philosopher.
After one philosopher finishes eating, they need to put down both forks so they become available to others.
The forks can be taken as they become available, but a philosopher cannot start eating before getting both forks.
The problem is how to design a concurrent algorithm such that no philosopher will starve (can forever continue to alternate between eating and thinking). We have a set of resources that needs to be shared between multiple actors.
In operating system terms, this means that each process which is currently running on the computer should receive a portion of CPU time, without being affected in any way by any other process.
The solution should avoid deadlocks.
Assuming we have the following algorithm:
This solution will fail because the system can reach a deadlock state.
When each philosopher has picked the fork to their left, all of them are waiting for the right fork to be available.
Therefore, the philosophers will eternally wait for each other to release a fork.
Resource starvation could also occur (Livelock) if we make a rule that the philosophers will put down a fork after waiting for x time for another fork to become available, and then wait x more before the next attempt.
Starvation can also occur if a philosopher finds at least one fork busy each time he wants to eat.
Arbitrator solution is one approach, and it guarantees that a philosopher can only pick up both forks or none by introducing an arbitrator (waiter). If a philosopher wants to pick up the forks, it must asks permission of the waiter.
The waiter will give its permission only to one philosopher at a time, until the philosopher has picked up both of their forks. The waiter can be implemented as a mutex.
This is a viable solution but not the perfect one, because if a philosopher is requesting the forks, all other philosopher must wait until the request has been fulfilled even if they have available forks.
***
Another solution (Tanenbaum’s solution) is to use a semaphore to represent a chopstick.
A chopstick can be picked up after we execute a wait operation on the semaphore, and released by executing a signal.
The philosophers alternate between 3 states: Thinking, Hungry, and Eating.
When the philosopher attempts to eat, they will enter a critical section, change its state to hungry, and pick up the chopsticks if the chopsticks are available (the state of the person to the left and to the right are not in eating). If the chopsticks are not available, he will wait for a change.
When the philosopher has finished eating, he will change its state to thinking. If any of his neighbors is in the hungry state, he will notify that they are safe to start eating.
No deadlocks are available, but the solution is not starvation-free.
The Producer-Consumer problem (also known as the “Bounded Buffer Problem”) is a multi-process synchronization topic, and it is based on two processes (the user and the consumer) which share a common buffer.
The problem uses two processes - the producer and the consumer.
The problem is to make sure that the producer won’t try to add the data into the buffer if it’s full, and the consumer won’t try to remove data from an empty buffer.
A wrong solution can result in a deadlock where both processes are waiting to be awakened.
A solution would be to use two semaphores – one for the full state, and one for the empty state.
We also use a binary semaphore (equivalent of the mutex) to have a critical section when accessing the buffer.
Initially, the full semaphore is initialized to 0, and the empty semaphore to the number of slots.
Solution - Producer
do {
//produce an item
wait(empty); // empty--;
wait(mutex); // mutex.lock()
//place in buffer
signal(mutex); // mutex.unlock();
signal(full); // full++;
} while(true);
At line 4, the producer is waiting on the empty semaphore. This means that if the semaphore is 0 (there are no empty – available slots) it will wait until one will be available.
We increase by 1 the mutex semaphore, so the consumer can access the buffer, and we also increase by 1 the full semaphore, because we added an item in the buffer.
do {
wait(full); // full--;
wait(mutex); // mutex.lock();
// remove item from buffer
signal(mutex); // mutex.unlock();
signal(empty); // empty++;
// consumes item
} while(true);
Because we signal the full semaphore, the consumer is notified of the change.
At line 3, the consumer is waiting on the full semaphore. This means that if the semaphore is 0 (there are no items in the buffer) it will wait until one will be available.
Because the item has been consumed, we increase the value of empty by 1, and signal the mutex so the producer can continue.
The readers-writers problem is an example of a common computing problem in concurrency.
The problem deals with the situation in which threads try to access the same shared resource at once.
We have multiple readers that do not modify the resource, and multiple writers that can modify the resource.
When a writer is modifying the resource, no other thread (readers nor writers) can access it at the same time.
We want to prevent more than one thread to modify the shared resource, and allow multiple readers to access the shared resource at the same time.
The problem can be categorized in three variants:
Assuming we have a mutex and an atomic integer to keep track of the number of readers:
mutex resource_access;
atomic<int> readers;
The first reader who enters the resource will lock the resource, so that no writer can access it, and unlock it when the last reader leaves the reading section.
Reader() {
while(1) {
readers++;
if (readers == 1)
resource_access.lock();
// read from resource
readers--;
if (readers == 0)
resource_access.unlock();
}
}
The writers will simply wait until the resource is accessible, write into it, and then release the mutex.
Writer() {
while(1) {
resource_access.lock();
// write data
resource_access.unlock();
}
}
The Cigarette Smokers Problem is another famous synchronization problem. It is similar to the producer-consumer problem but has extra constraints.
Assume a cigarette requires three ingredients to make and smoke: tobacco, paper, and matches.
There are three smokers around a table, and each of them has an infinite supply of one of those ingredients.
There is also an agent who enables the smokers by randomly selecting two of the supplies and placing them on the table.
The smoker who has the third supply should remove those two items from the table, use them along with their supply to make a cigarette, and then smoke for a while.
Afterwards, the agent places two new random items on the table.
The problem is to make sure that the smoker which has the 3rd ingredient will benefit from those placed on the table.
When the agent makes two items available, every smoker thread can use one of them, but only one can use both.
If the agent makes tobacco and paper available, both the smokers with tobacco and paper want the other resource, but neither can smoke because they don’t have tobacco.
If either of them consumes one resource, the tobacco smoker will not be able to smoke, creating a deadlock.
Assuming we have a mutex for the resources and semaphores for the smokers and the agent:
mutex global_resource;
semaphore agent, match, paper, tobacco; // init with 0
The agent will signal only the smoker that is supposed to be awaken by the action of adding two resources on the table.
void agent() {
do {
global_resource.lock();
int random_value = rand(1,3);
switch (random_value) {
case 1:
// Put paper and tobacco on table
signal(match); // match++
break;
case 2:
// Put match and tobacco on table
signal(paper); // paper++
break;
case 3:
// Put match and paper on table
signal(tobacco); // tobacco++
break;
}
global_resource.unlock();
wait(agent);
} while(true);
}
The code for the smokers is similar, now I’ll show only for one of them.
void smoker_with_matches() {
wait(match); // sleep until the signal is thrown
global_resource.lock();
// pick up paper and tobacco from the table
// smoke
global_resource.unlock();
signal(agent);
}
The signal at the end is not necessary, since the agent is in a while loop, and it will wait the mutex (line 3) until it will be unlocked again (line 7).
Data race occurs when more than two threads access the same memory and one of them is a write.
Polymorphism – “poly” (many) + “morphe” (form)
Binary search: split the range in half and check it from there. Based on the result, you will reduce half of the work by knowing in which half is the problem contained.